
天天新闻

天天在线汽车

天天在线文旅

天天财经116

天天在线App
天天新闻
天天在线汽车
天天在线文旅
天天财经116
天天在线App
英伟达凭借GPU与CUDA生态构筑的护城河,让无数企业甘愿为高昂的硬件成本与毛利率买单。因为在技术探索期,算力供给的稳定性远比性价比重要。但当AI应用进入规模化商用阶段,那些曾对GPU价格无动于衷的科技巨头们,正悄然将目光投向更高效的定制化方案。正如比特币挖矿从CPU到GPU再到ASIC的演进轨迹,当算法架构逐渐固化,通用计算芯片的灵活性反而成为桎梏。
云端服务商对电费的敏感度、企业级客户对投资回报率的苛求,都在推动一个共识:在算力需求爆炸的今天,为特定场景定制的ASIC芯片,或许才是平衡性能与成本的最优解。
大模型算法或进入瓶颈期
当AI应用进入规模化商用阶段,成本问题逐渐凸显:Grok3训练消耗约20万块H100 GPU(成本约5.9亿美元),ChatGPT5训练成本达5亿美元,远超早期GPT3仅140万美元的投入。这种指数级增长背后,是Transformer架构的局限性:其二次复杂度Attention机制导致算力需求剧增,预训练红利逐渐触顶。
大模型的本质仍是基于概率权重的统计模型,其"幻觉"与表现力的平衡始终是难题。从信息熵的角度看,早期能力提升依赖技术优化,后期则受限于数据丰度——Grok3与GPT5的能力已接近当前数据环境下的挖掘极限。尽管Transformer架构下的能力天花板逐渐显现,但突破现有技术路线仍充满不确定性:若新架构的起跳标准需超越GPT5,行业准入门槛将大幅提高,可能延缓技术迭代速度。
尽管如此,大模型在垂直领域的应用价值已被验证。在音乐创作、代码生成等场景中,其效率提升显著,部分从业者已借此实现商业化。但所谓"统一大模型"的概念正被打破——行业应用工具的定制化开发或成主流。各行业龙头企业更倾向于在现有工具中嵌入AI模块,兼顾效率与系统兼容性;对创业团队而言,精准识别细分需求并落地解决方案更为关键。例如音乐生成领域,仅掌握大模型技术远不够,还需深度理解音乐特性;To C端则面临收费模式与流量入口的双重挑战——巨头通过免费策略控制入口,再以其他业务变现,中小企业的突破点更可能集中在To B领域。
当前,大模型能力已不再是行业落地的核心矛盾,如何将技术优势转化为实际场景的应用价值,才是决定未来格局的关键。
ASIC是最优解?
如果把芯片世界比作一个工具箱,那么ASIC就是那个为特定任务量身打造的"专业工匠"。不同于GPU这个"全能选手"(既能挖矿又能跑AI),ASIC(专用集成电路)从设计之初就锁定单一目标——就像专门为拧螺丝设计的电动起子,虽然只能拧螺丝,但效率是普通螺丝刀的百倍。
以比特币挖矿为例,早期矿工用CPU计算,后来发现GPU并行计算能力更强,但真正让挖矿实现产业化的,是比特大陆推出的ASIC矿机。这种芯片把所有电路资源都用于执行SHA256哈希算法,就像把整个芯片变成一台"算力永动机",单位能耗的挖矿效率是GPU的千倍级别。这种极致优化带来的结果是:当比特币网络难度飙升时,只有ASIC能保持经济可行性。
这种特性在AI领域同样关键。英伟达GPU虽然能处理各种算法,但运行Transformer架构时,大量晶体管被用于通用计算而非特定任务。就像用瑞士军刀切菜,虽然能用但远不如专业菜刀高效。而ASIC可以把所有电路资源分配给矩阵乘法、激活函数等核心操作,理论上能实现10倍以上的能效比提升。
运维成本的差异更直观。一块NVIDIA GPU功耗约700瓦,运行大模型时每小时电费约0.56元(按0.8元/度计)。而同等算力的ASIC芯片功耗可控制在200瓦内,同样任务每小时电费仅0.16元。对于需要部署数万张卡的云服务商,这种差距每年可能节省数千万度电——相当于一个小型电厂的年发电量。
不过ASIC的"专业病"也很明显:一旦算法升级或任务变更,这些定制芯片就可能沦为"电子废品"。就像专门为胶片相机设计的镜头,在数码时代毫无用武之地。因此它更适合算法相对固化的场景,比如云端推理服务、自动驾驶感知系统等需要长期稳定运行的任务。
当前AI产业正面临关键转折:当大模型训练成本从GPT3时代的千万级飙升至Grok3的数十亿美元级,连科技巨头也开始重新评估技术路线。就像当年从CPU转向GPU一样,现在或许轮到GPU让位给更专业的ASIC。
国内设计服务厂商有望受益良多
定制加速计算芯片(ASIC)正成为AI算力革命的核心驱动力。据预测,2028年全球定制加速计算芯片市场规模将达429亿美元,占加速芯片市场的25%,2023-2028年复合增长率达45%。这一爆发式增长源于AI模型对算力需求的指数级攀升:训练集群已从万卡级向十万卡级演进,而推理集群虽单集群规模较小,但百万级部署量将形成更庞大的市场需求。
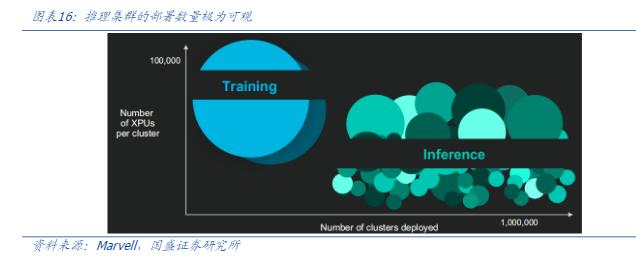
科技巨头正加速布局自研ASIC以抢占先机。谷歌推出第六代TPU Trillium芯片,重点优化能效比,计划2025年大规模替代TPU v5,并打破此前仅与博通合作的模式,新增联发科形成双供应链,强化先进制程布局。亚马逊AWS以与Marvell联合设计的Trainium v2为主力,同步开发Trainium v3,TrendForce预测其2025年ASIC出货量增速将居美系云服务商首位。Meta在首款自研推理芯片MTIA成功部署后,正与博通开发下一代MTIA v2,聚焦能效与低延迟架构,适配高度定制化的推理负载需求。微软虽仍依赖英伟达GPU,但自研Maia系列芯片已进入迭代阶段,Maia v2由GUC负责量产,并引入Marvell参与进阶版设计,分散技术与供应链风险。
芯片设计厂商亦迎来增长机遇。博通2025年第二季度AI半导体收入超44亿美元,同比增长46%,其定制AI加速器(XPU)业务受益于三家客户百万级集群部署计划,预计2026年下半年推理需求将加速释放。Marvell主导的3nm XPU计划已获得先进封装产能,2026年启动生产,并与第二家超大规模客户展开迭代合作。国内市场同步加速,阿里巴巴平头哥推出Hanguang 800推理芯片,百度集团建成自研万卡集群(昆仑芯三代P800),腾讯控股通过自研Zixiao芯片与投资燧原科技形成组合方案。
这场变革的本质是算力供给从通用走向专业化的转型。当AI应用进入规模化落地阶段,ASIC凭借针对特定算法的极致优化能力,正在重新定义算力经济的成本结构与技术路线。












